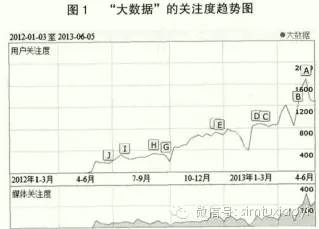
1 引 言 2011 年5月,咨询行业的顶级公司麦肯锡(McKinsey)在《大数据:创新、竞争和生产力的下一个前沿领域》(BigData: The Next Frontier for Innovation, Competition andProductivity)报告中指出,数据已经渗透到每一个行业和业务职能领域,逐渐成为重要的生产因素;而人们对于海量数据的运用将预示着新一波生产率增长和消费盈余浪潮的到来。 在若干年前,人们可能无法想象风马牛不相及的两种商品——尿布与啤酒,在沃尔玛超市竟然是放在一起的,而且销售数据还显示摆放在一起的举措使尿布和啤酒的销量都大幅增加。原来在美国,被年轻妈妈吩咐外出购买孩子尿布的年轻爸爸顺带也购买了他们钟爱的啤酒。该规律是由沃尔玛的后台数据挖掘专家从浩如烟海且杂乱无章的商品销售数据中获得的。另外一个被人们津津乐道的大数据经典案例是,超市的销售经理比父亲更早地发现其未成年女儿怀孕的事实,且展开了孕妇用品的推介。 笔者在 CNKI(中国知网)检索主题为“大数据 and 图书馆”的学术论文发现,图书馆学领域已公开发表的文献共 1 1 篇,相对于其他领域的研究成果较少;在百度指数(http://index.baidu.com)检索“大数据”后可以清楚地看到,“大数据”在国内是从 2012 年第二季度开始受到人们普遍关注的,且至 2013 年的第二季度关注度一直呈迅猛上升的趋势(见下页图 1)。这是由于 2012 年 3 月,奥巴马政府发布《大数据研究和发展倡议》(Big Data Research andDevelopment Initiative)并首批资助2亿美金开展重大研究 ,美国政府的大动作引发了全球的议论热潮。当前阶段,在任一国家、地区、行业或领域,大数据及其相关话题都是人们关注的焦点。虽然尿布与啤酒及超市案例发生在企业界,看似与提供公共服务的图书馆没有直接联系,但案例背后的逻辑或范式却应对图书馆有所启发。随着人们对大数据的关注度不断攀升,尽管目前大数据技术远未成熟,还不能进行广泛的应用,但大数据思维却值得我们思考和学习,而且这也是在大数据时代全面来临之时广泛应用这一强大工具的必备前提。基于此,笔者以澳大利亚“图书馆立方”项目为例,探讨在图书馆信息服务的实际业务中,如何运用大数据思维整合、改进图书馆信息服务工作。
2 大数据和大数据思维2.1 大数据 大数据,也称海量数据,主要依据存储数据的大小是否达到 PB 级或 EB 级①。国际数据公司 IDC2011 年发布的报告指出,全球信息总量每两年翻一倍。仅2011年全球数据总量就为1.8ZB,IDC 预测到2020 年其将增长到35ZB[4]。关于“大数据”,目前尚没有统一、标准或
权威的定义。但显然,数据“大”不等于“大数据”。实际上,大数据不是对数据规模的定量描述,而是一种在类型繁多、数量庞大的多样化数据中进行的快速信息提取的技术和思维。关于大数据特点,已有文献做了大量的研究和总结,如 4V(Variety、Velocity、Volume、Value)[或“4V+1C(”Variety、Velocity、Volume、Vitality和Complexity),在此笔者不再赘述。2.2 大数据思维 大数据思维,即大数据技术的哲学基础或内在逻辑,笔者认为其具有规律性、无偏性、关联性和开放性 4 个特征。 (1)规律性 大数据技术背后的逻辑——看似杂乱的海量数据里必然隐藏着规律性的东西,每个数据背后都是对真实个体行为、心理、思想等的客观记录,而人的行为模式、心理机制相对整个人类群体而言是极其稳定的,即会呈现规律性。但这些规律在数据分析和挖掘前是不知道的,如尿布与啤酒案例。 (2)无偏性 大数据技术的一个重要学科基础是统计学,因此大数据思维体现统计学的思维特点或者是对其的突破。统计学的一项重要成就是解决“代表性”问题,过去囿于现实因素,绝大多数的调查只能通过抽样的形式,但抽样始终是有偏的,不能代表总体,于是要求统计学致力于保证和努力提高代表性。随着大数据技术的出现与应用,人们发现直接研究总体比较可行。大数据研究专家涂子沛认为,“数据革命实际上是统计学的革命”。 (3)关联性 大数据是由一个个数据、数据库、数据集和数据群不断累加形成的,数据越多其价值才可能越大。因此在进行数据挖掘时,既要注重数据群内部数据集与数据集之间的关联,更要注重数据群与数据群之间的关联,以挖掘更多的隐性价值。 (4)开放性 所谓开放性,指对可能的结论先不带预设、预期,而是按照已获得验证的可靠的科学方法和流程去做研究。大数据研究便是不带预设的,在得到结论之前不知道自己想要什么结论,即“未知的未知”(UnknownUnknows)。大多数传统商业情报(Business Intelligence)工具都有个重大局限,即专注于“已知的未知”(KnownUnknows),先知道问题是什么,然后去找答案,由分析人员预先确定收集什么数据[3]。当然,要实现“未知的未知”,前提是拥有大数据和配备相应的分析技术或系统。 大数据既是一种技术,更是一种思维。对图书馆而言,关键的是借助大数据思维创新其信息服务模式、扩大信息服务范围和提高信息服务质量,同时也可为其他社会组织提供大数据源和创造信息价值,而大数据技术本身只是实现目标的工具。2.3 图书馆和大数据 在图书馆领域讨论大数据概念、开展相关研究,不可避免地要首先回答“图书馆有无大数据”、“图书馆的大数据是什么”这样的问题。在已有的研究图书馆与大数据关系的文章中,有人把图书馆自建或外购的数字资源认为是图书馆的大数据[4,7],对此笔者不敢苟同。虽然这些数字资源本质上是以 0 和 1 的“数据”形式存储在服务器上,而且达到了 P B 级,但它不是大数据意义上的“数据”,它们是信息、知识。在图书情报学的研究领域,数据、信息和知识既相互联系又显著区别[8-9]。大数据在被调用分析前是无序的,不能直接被利用,而图书馆的论文数据库等信息资源是可直接阅读、学习的文献和知识。但图书馆的 MARC(Machine Readable Catalogue,机器可读目录)数据、读者的借阅记录、用户信息行为数据(如电子数据库的访问记录)等可以是大数据或者说将可能成为大数据。大数据思维昭示的是隐藏在海量数据背后的某些规律性的东西或数据群与数据群之间的关联关系。 国内单个图书馆的 MARC 数据、读者的借阅记录数可能还达不到 PB 级,从规模上不属于大数据,但并不妨碍图书馆开始运用大数据思维。图书馆本可以比现在拥有更多的数据,但由于尚未学习、内化大数据思维,没有及时收集、存储现在每天都在产生的用户信息行为等大数据,更遑论对这些数据的挖掘、开发和研究。3 大数据思维的应用案例3.1 澳大利亚“图书馆立方”项目3.1.1 “图书馆立方”项目介绍 2009年,卧龙岗大学图书馆(University of WollongongLibrary,简称UWL)与该校绩效指标管理中心(PerformanceIndicator Unit,简称PIU)合作开发了“图书馆立方”(LibraryCube,简称 LC)项目,将学生的图书馆使用记录与 PIU 已有的数据库相关联,一方面评估图书馆在教学活动中的影响和价值,另一方面也希望通过收集反馈信息以扩大图书馆信息资源的影响和提高图书馆的价值,同时为学校的教学政策制定提供数据支撑。“图书馆立方”包括 3 个部分:价值立方、营销立方和流程改进立方。 (1)价值立方(Value Cube) 该立方已开发且正在使用中,它围绕学科教学活动开展,用于评价图书馆信息资源的使用对学生成绩的影响。UWL 可以通过该系统看到不同使用频次的学生的基本信息特征。该立方的数据每学期更新一次,需要等到期末学生成绩汇总后再导入。 (2)营销立方(Marketing Cube) 营销活动客观要求立方每周更新一次数据,显然价值立方不能满足要求,因此营销立方不包括学生成绩的数据,只包括学生的基本信息数据和学生使用图书馆电子资源类型(如电子书、电子阅读材料或所访问数据库的名称等)的数据。目前该立方还在开发当中。 (3)流程改进立方(Process Improvement Cube) 该立方还尚未开发,但其数据将依学科分类统计,目的是将图书馆的影响扩大到教学领域以外。3.1.2 “图书馆立方”项目的发现 Cox和Jantti通过“图书馆立方”的数据分析发现,卧龙岗大学学生的学习成绩与其利用图书馆信息资源(电子或纸质资源)的情况密切相关,具体结论详见图 2、3 和 4。
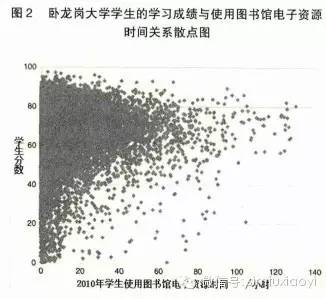
图 2 显示的是卧龙岗大学 21 000 多名学生的学习分数和使用图书馆电子资源时间的二维分布。每个点的横坐标表示该学生 2010 年使用图书馆电子资源的总时长(小时),而纵坐标表示该学生 2010 年度的加权平均分数。上述散点图呈现出一定形状,即随着使用图书馆电子资源时间的增加,学生的分数聚集层也在提升。
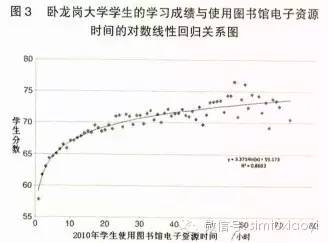
图 3 中每个点的横坐标代表卧龙岗大学学生 2010 年内使用图书馆电子资源的时间分组,如 0~1 小时、1~2 小时;纵坐标代表落入该分组的所有学生的平均成绩。如此简化后,便可以挖掘散点图中所隐藏的统计学意义上的关系。曲线代表的正是学生成绩与使用电子资源时间之间的对数线性回归关系,且回归方程y=3.371 4ln(x)+59.173的判定系数 R2=0.868 3,说明该曲线非常好地拟合了两者之间的关系。简言之,在卧龙岗大学,学生使用图书馆电子资源的时间越长,其学习成绩可能越好;或者,学习成绩越好的学生可能越长时间地使用图书馆的电子资源,这充分体现了高校图书馆的重要性和价值创造作用。
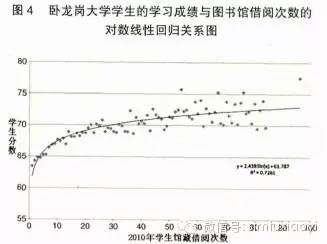
图4 与图3 类似,但其反映的是学生馆藏借阅次数与学习成绩之间的关系,借阅馆藏次数越多的学生的学习成绩可能越好。同样地,Cox和Jantti得出两者的对数线性回归方程y=2.439 3ln(x)+61.787,方程的判定系数R2=0.726 1,略小于前述方程的0.868 3。这表明图书馆纸质馆藏和电子信息资源与学生成绩之间的关系存在差异。Cox和Jantti指出造成上述差异的原因可能是:(1)2010 年卧龙岗大学有接近 30% 的学生没有借过 1 本书,而没使用电子资源的学生只有 8%;(2)馆藏借阅次数最多和使用电子资源时间最长的学生平均分数之间差别较大,且它们与相对应的从不借阅馆藏或使用电子资源的学生的平均分数之间的差距分别是 11 分和19 分。其实,这从另一个侧面反映出随着信息技术的不断发展人们信息使用习惯的变化,即电子资源比传统的纸质资源得到了更广泛和便利的使用,这为图书馆的信息资源建设传递了重要信号。 上述研究表明,一方面“图书馆立方”项目的开展非常有利于图书馆向学校管理委员会和其他上级机构很好地展示其为学校的教学活动创造的价值;另一方面也获得了一些预期之外的科学结论(如性别、年龄、成绩等社会变量与图书馆用户行为之间的关系),进而为图书馆未来的推广活动提供准确的细分目标群体,以提高活动的针对性和执行效率。3.2 “图书馆立方”项目的启示 如果从数据规模上讲,UWL 使用该校 21 000 多名在校学生的成绩数据、图书馆信息资源使用记录数据,还不能称之为“大”数据研究。但前文笔者总结的大数据思维特征在该研究中得到了全面的体现。Cox和Jantti采用全样本,即卧龙岗大学全体学生的图书馆访问、借阅数据及学习成绩数据,体现无偏性;在开展“图书馆立方”项目前,没有预先研究假设,体现开放性;将图书馆数据群与 PIU 成绩数据群联合分析,体现关联性;最后的研究结果很好地证明了规律性的存在。 关于研究学生学习成绩或学术成就与其使用图书馆信息资源之间关系的思路并不新颖,但过往的研究采用的研究方法是问卷调查、抽样调查等,导致研究结论的偏差性和部分信息的缺失,这些是代表性无法克服的缺陷。然而,随着信息技术的进步,研究方法和分析技术得到了极大的提高,全样本研究已成为可能,这不但解决了代表性难题,而且发现在“全样本”研究框架下,往往能获得更多的预期外的信息量和研究成果。例如,上述案例发现 2010 年卧龙岗大学完全没有使用电子资源的学生只占 8%,而没有借过一本图书的学生接近 30%,这反映出用户信息阅读习惯的趋势性变化。 如果 UWL 的目光仅限于自身的读者借阅数据,其也可以分析出馆藏文献流通的特征,如哪些类型、主题文献的借阅率高,但这是停留在结构化数据层次的分析。这样的分析报告很难向上级机构或其他有关管理机构展示图书馆的价值创造活动,也很难对 UWL 根据“图书馆立方”项目研究成果得到的细分目标群体展开有针对性、能够提升价值的图书馆服务推广活动。虽然国内图书馆目前尚无此方面的客观要求或主观目标,但这是图书馆未来会面临的现实问题。因此,图书馆非常有必要学习并内化大数据思维,不仅要关注自身的数据群,还应注重与其他组织数据群的互动,深入了解用户信息行为改变背后的信息需求变迁,考虑如何更好地整合图书馆的信息服务资源,以期发挥更大的效用,甚至可能引发一些服务内容或模式的变革。3.3 大数据思维在图书馆效益评价中的应用 国外关于图书馆经济价值的评价研究目前主要有两种方法:成本节约法(Cost Saving Approach)和条件价值估计法(Contingent Value Method)[11]。这两种方法都涉及到问卷调查,因此也就无法回避样本的代表性问题。 大数据思维一个重要的特征就是全样本,而这也正是信息技术进步对研究方法或研究范式所带来的发展。若干年前,受检索技术快速发展的冲击,图书馆业界思考 MARC格式是否过于复杂和精细以至包含了很多“无用”信息。但是,当大数据概念兴起和大数据思维不断被人们接受时,详细描述馆藏文献的 MARC 数据事实上是有“大用”的。以成本节约法为例,其介绍 MARC 数据如何可以准确且动态地评价图书馆的经济效益。成本节约法的逻辑很简单,假设图书馆不存在,读者使用图书、期刊等信息资源就必须通过其他渠道,所以可以把读者通过其他途径获得信息资源的成本视作图书馆“创造”的价值。就图书而言,图书馆作为公共的信息服务机构,借阅是免费的。当不能从图书馆借阅时,读者需要自行购买,或通过实体书店或网上书店购买。因此,如果某本图书一年流通了 N 次,而该图书的价格是 C 元,即图书馆在该本图书上创造的价值就是C*N 元。当完整的 MARC 数据和图书流通数据一关联,便可以准确地计算出某图书馆一年内所有图书创造的经济价值 V= ∑ Ci *Ni。在进一步深入评价时,还需要考虑加入购书的平均折扣系数和物价变动系数等,本文对此不作展开。 这个研究思路在过去是有的,但由于数据和技术的缺乏,只能退而求其次,采用统计调查法,但由于图书卷帙浩繁、品种万千,所得结论的可靠性常受质疑。现在大数据技术则可能很好地解决相关问题,甚至可以缩短到每月、每周动态地计算图书馆创造的馆藏价值。4 图书馆的“大数据”准备工作4.1 收集、存储相关数据 对图书馆而言,目前可以着手也是应该进行的工作是注重收集和存储用户信息行为数据,一方面是逐渐将其累积成大数据,为将来各项应用做好充分准备;另一方面是借助已有的数据分析手段和研究方法,透过用户信息行为数据了解用户需求的变化特点,细分用户群体,进而指导图书馆信息资源建设和信息服务整合。 一定规模以上的图书馆(如省级公共图书馆),每天服务的用户人次与大型企业每天的客户数量类似,其中都蕴含着大量的用户行为数据,这些数据图书馆应予以重视并收集。以高校图书馆为例,用户在校园网的 IP 范围内可以直接登录图书馆系统并使用图书馆的电子资源,但目前大多数情况是用户信息行为数据(如数据库的检索时长、检索词、下载文献的主题等),并没有被图书馆有意识、有目的地记录和存储。又如,多数高校图书馆都已实现学生进入图书馆必须刷卡,但出馆时则不必,如此关于用户出入图书馆实体场所的数据便少了一半。姜山等人认为用户这类半结构化和非结构化数据,虽然价值密度较小,但如能全面收集则有利于分析用户相关偏好,帮助图书馆提供最有用的信息服务[4]。4.2 学习大数据思维 如前所述,大数据时代最重要的不是大数据,也不是大数据技术,而是大数据思维。思维是创新的源泉。学习并内化大数据思维对图书馆迎接、拥抱大数据时代至关重要。图书馆是整个社会中信息资源的集散节点,如果用户无法从图书馆获得满意的服务就会转向其他组织或机构,而用户流失会动摇公益性机构的存在基础。因此,图书馆应该组织学习大数据思维,了解大数据在其他领域的发展和应用,不论是商业领域还是社会领域。在没有学习和了解之前,图书馆的管理层或馆员都很可能因对大数据望文生义而错误理解,认为大数据技术高深莫测,容易产生距离感。 大数据与我们的日常行为密切相关,图书馆的经济效益评估和信息服务工作也都能应用到大数据思维。有条件的图书馆可以尝试类似“图书馆立方”项目的实践,充分了解用户信息行为及其不断变化的需求,同时也可以客观地量化评估自身的经济价值,从而不断改善信息服务和提高图书馆的重要性。